What do we mean by ‘unstructured data’?
Unstructured data refers to health information that is not organised in a pre-defined way – for example, there isn’t a pre-set ‘drop down’ list of options that the doctor clicks on. Examples of unstructured data include imaging data, for example data from heart or brain images, ‘free text’ sections of patient medical notes, and electrocardiograms (‘ECGs’).
Find out more about imaging data here.
Why is ‘unstructured data’ important for cardiovascular disease research?
There is a huge amount of potentially useful information in this type of data, which is currently underused for research because it is harder to analyse. We want to improve access to this type of health information, improve the quality of it, and use it to be able to answer key research questions in cardiovascular disease. We hope this will mean that this type of data can be increasingly used to improve the treatment and management of cardiovascular disease.
What are we doing?
To explore how imaging data could be used to better understand cardiovascular disease we organised a workshop, bringing together over 80 imaging, cardiovascular, data science and computer science researchers, healthcare professionals, relevant societies and companies, data custodians and patient/public representatives. You can read the full workshop report here.
As a step towards establishing national priorities for cardiovascular imaging research, we organised a prioritisation exercise to gather the opinions of a diverse range of stakeholders. You can read more about the findings here and in the infographic below.

You can find out more about this work in our webinar entitled “Using imaging data to better understand cardiovascular disease”.
Public and Patient Engagement
In partnership with our public advisory group, we carried out a survey to find out what types of cardiovascular disease research members of the public think are most important. The results of this survey will guide the work across the Centre.
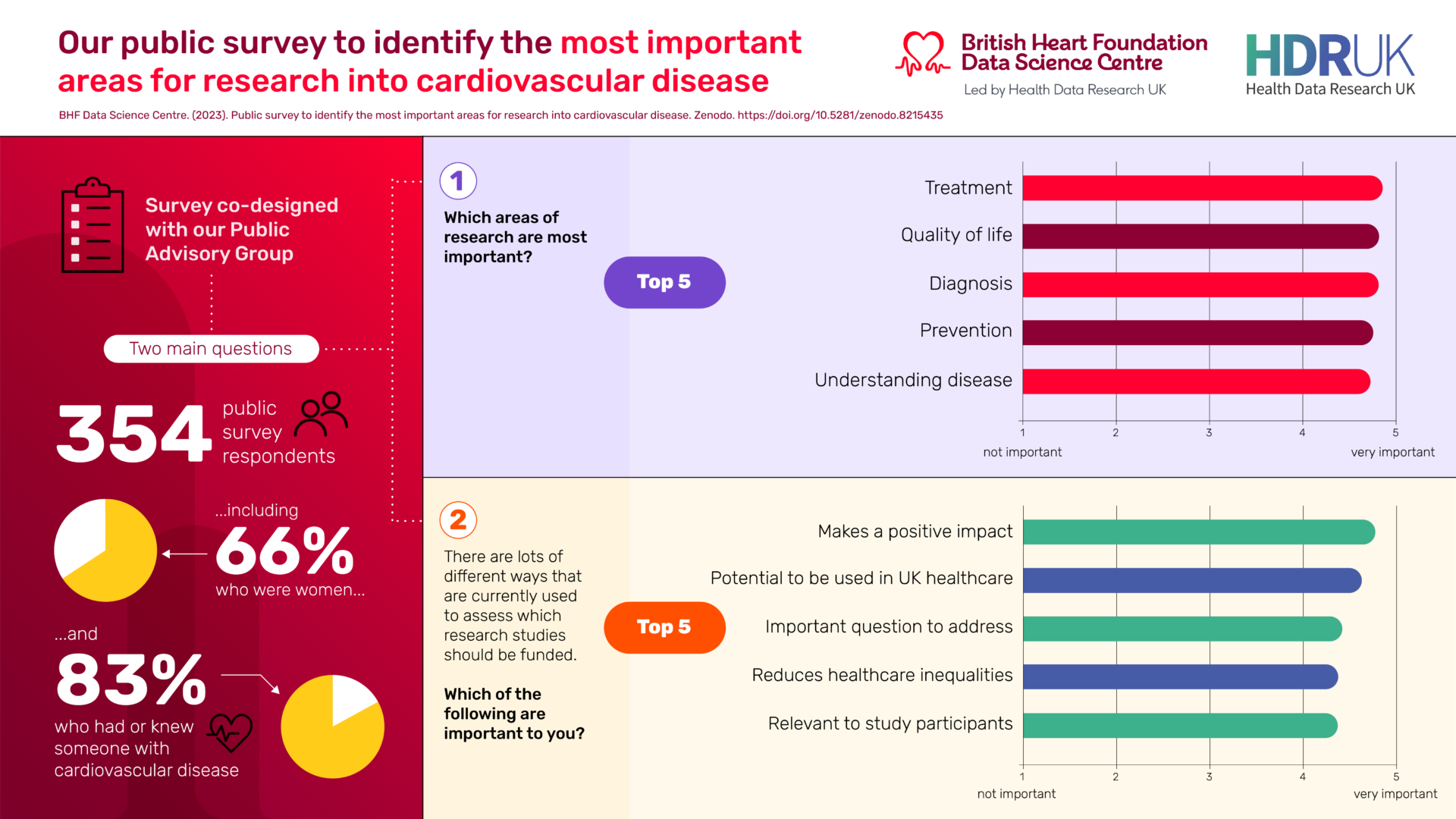
You can learn more about this survey and hear the thoughts of two members of our PPIE group, Phil Blakelock and Julian Meldrum, in our webinar entitled “Amplifying patient and public voices – sharing results from our cardiovascular research priorities survey” here.
Areas of work
Find out more about our data-led research.
CVD-COVID-UK / COVID-IMPACT
One of seven National Flagship Projects approved by the NIHR-BHF Cardiovascular Partnership, linking population healthcare datasets across the UK to understand the relationship between COVID-19 and cardiovascular diseases.
Learn more…
Whole Population Data
Better use of nationally-collated, structured, coded data: accessing, improving and using linked, national, population-wide health data.

Smartphones and Wearables
Exploring how data from apps and wearables, linked to other health datasets, can inform trajectories of cardiovascular health and disease.

Defining Disease
Developing methods to define cardiovascular health and disease in computable form through a collaborative network of expertise that provides a world-leading, open, cardiovascular phenotype library of tools and protocols.

Clinical Trials
Developing platforms for efficient, cost-effective trials, using routine health data to recruit and follow patients with cardiovascular conditions.

Cohorts
Facilitating the linkage of large, ‘omics-rich’ cohorts to electronic health records to better understand the causes of cardiovascular diseases.
Diabetes Data Science Catalyst
This exciting partnership between the BHF Data Science Centre, Diabetes UK and HDR UK aims to develop improvements in our understanding of the link between cardiovascular diseases and diabetes.

Stroke Data Science Catalyst
This five-year partnership between the British Heart Foundation (BHF) Data Science Centre, Health Data Research UK (HDR UK), the Stroke Association, and the BHF – will enable approved research teams to use data from real-world settings, including hospitals, GPs and pharmacies, to improve our understanding of stroke risk factors and open the door to better prevention and treatment.